
Sklearn minmaxscaler is used to scale the dataset based on the minimum and maximum values. For each value in a feature, sklearn MinMaxScaler subtracts the minimum value in the feature and then divides it by the range. The range is the difference between the original maximum and the original minimum. MinMaxScaler preserves the shape of the original distribution. In this tutorial, we will learn how the min-max scaler scales the dataset and will solve various examples to normalize datasets.
What is Sklearn Minmaxscaler?
The sklearn min-max scaler is used to normalize data. The question is why do we need to normalize data?
Actually, training a machine learning model is all about manipulating and finding hidden trends in datasets. So, it is recommended to have a dataset in a specific range so that different values with high numbers do not have more weight.
In min-max scaling, we have to estimate min and max values accurately. The sklearn minmaxscaler uses the following formula.
- y = (x – min) / (max-min)
The min and max are the minimum and maximum values of the data which need to be normalized. Let us say we have an x value of 13, a min value of 6, and a max value of 50. Then the minmaxscaler will normalize it to:
- y = (13-6)/(50 – 6)
- y = (7)/(44)
- y = 0.150
You can see that if an x value is provided that is outside the bounds of the minimum and maximum values, the resulting value will not be in the range of 0 and 1. You could check for these observations prior to making predictions and either remove them from the dataset or limit them to the pre-defined maximum or minimum values.
How to apply MinMaxScaler?
The implementation of minmaxscaler is very easy. In Sklearn module, there is already a built-in function minmaxscaler() is used to scale the datasets. All we need is to initialize the scaler and use the fit_transform() method and provide the dataset.
The important question is when to use the minmaxscaler? Usually, the scaling of the dataset is preferred when you have various columns and each column has values in different ranges. This might effect the training process of machine learning models.
If you are training a machine learning model on your dataset and the data has different ranges values in different columns, then scaling is recommended. In case of supervised machine learning model, you are required to apply the scaling on only the input values, don’t apply the scaling on the target column.
Examples of Sklearn Minmaxscaler on Data Frame
Now, we will apply sklearn minmaxscaler to normalize the dataset by taking various examples. Before going to the implementation part, make sure that you have installed the sklearn module on your system. You can use the pip command to install the sklearn module on your system.
We will apply sklearn minmaxscaler on:
- User-defined data
- specific column
- data frame
You may also like to read about the ARIMA model.
User-define Dataset
Now we will create a simple dataset. We will convert the data into a NumPy array and scale the data using sklearn minmaxscaler.
# importing the modules
from numpy import asarray
from sklearn.preprocessing import MinMaxScaler
# creating user-defined dataset
data = asarray([[10, 0.001],
[80, 0.05],
[34, 0.005],
[81, 0.07],
[43, 0.1],
[76,0.07]])As you can see, we have created a dataset. Notice that the range of the first column is much higher than the range of the second column. Let us use the box plot to see how each of the columns is distributed.
# importing seaborn module
import seaborn as sns
# plotting box plot
sns.boxplot(data=data)Output:
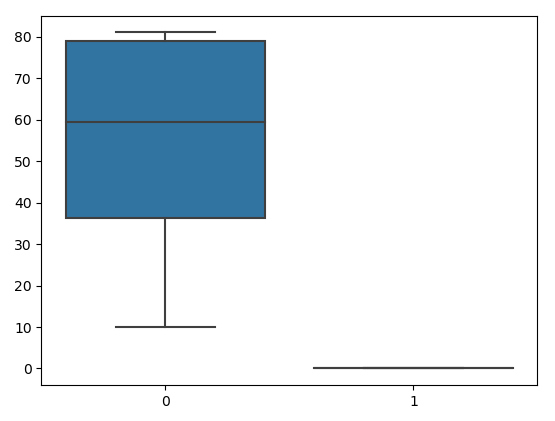
The second column distribution/range is much less than the first one. Now, we will apply a min-max scaler to normalize the dataset.
# applying min-max scaler in python
scaler = MinMaxScaler()
# fitting min-max scaler in python
scaled = scaler.fit_transform(data)
# importing seaborn module
import seaborn as sns
# plotting box plot
sns.boxplot(data=scaled)Output:
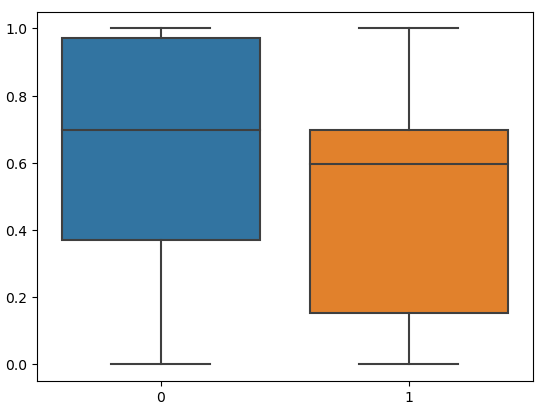
As you can see the data is now scaled now in a specific range.
Example-2: Specific Column
We can also apply the sklearn minmaxsacler on a specific column rather than on the whole dataset. We will scale the first column of the dataset.
# importing sklearn standardscaler
from sklearn.preprocessing import StandardScaler
# define standard scale
scaler = MinMaxScaler()
# transform data
scaled = scaler.fit_transform(data[:, :1])
# plotting the data
sns.boxplot(data=scaled)Output:
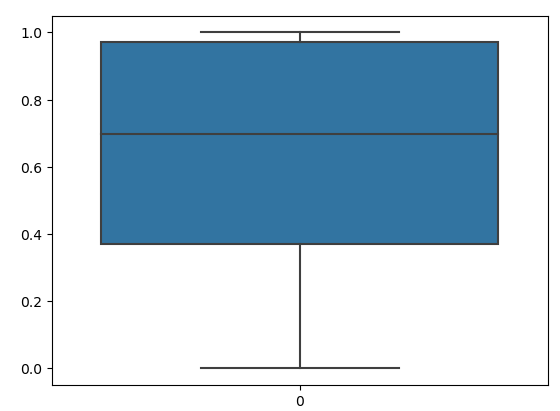
As you can see, the data is scaled in a specific range now.
Example-3: MinMaxScaler on Dataframe
Let us now apply the sklearn minmaxscaler on a data frame. We will first import the dataset using pandas and apply sklearn minmaxscaler.
# importing pandas
import pandas as pd
# importing dataset
data = pd.read_excel('data.xlsx')
# define standard scale
scaler = MinMaxScaler()
# transform data
scaled = scaler.fit_transform(data['Age'])
# plotting the data
sns.boxplot(data=scaled)Output:
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
/tmp/ipykernel_31375/616191229.py in <module>
9
10 # transform data
---> 11 scaled = scaler.fit_transform(data['Age'])
12
13 # plotting the data
~/.local/lib/python3.10/site-packages/sklearn/base.py in fit_transform(self, X, y, **fit_params)
865 if y is None:
866 # fit method of arity 1 (unsupervised transformation)
--> 867 return self.fit(X, **fit_params).transform(X)
868 else:
869 # fit method of arity 2 (supervised transformation)
~/.local/lib/python3.10/site-packages/sklearn/preprocessing/_data.py in fit(self, X, y, sample_weight)
807 # Reset internal state before fitting
808 self._reset()
--> 809 return self.partial_fit(X, y, sample_weight)
810
811 def partial_fit(self, X, y=None, sample_weight=None):
~/.local/lib/python3.10/site-packages/sklearn/preprocessing/_data.py in partial_fit(self, X, y, sample_weight)
842 """
843 first_call = not hasattr(self, "n_samples_seen_")
--> 844 X = self._validate_data(
845 X,
846 accept_sparse=("csr", "csc"),
~/.local/lib/python3.10/site-packages/sklearn/base.py in _validate_data(self, X, y, reset, validate_separately, **check_params)
575 raise ValueError("Validation should be done on X, y or both.")
576 elif not no_val_X and no_val_y:
--> 577 X = check_array(X, input_name="X", **check_params)
578 out = X
579 elif no_val_X and not no_val_y:
~/.local/lib/python3.10/site-packages/sklearn/utils/validation.py in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_all_finite, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)
877 # If input is 1D raise error
878 if array.ndim == 1:
--> 879 raise ValueError(
880 "Expected 2D array, got 1D array instead:\narray={}.\n"
881 "Reshape your data either using array.reshape(-1, 1) if "
ValueError: Expected 2D array, got 1D array instead:
array=[21. 18. 20. 65. 18. 24. 45. 35. 23. 32. 34. 31. 43. 32. 20.].
Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.The reason why we got this error is that we need to do some transformations before applying sklearn minmaxscaler on a data frame.
# importing numpy array
import numpy as np
# define standard scale
scaler = scaler = MinMaxScaler()
# transform data
scaled = scaler.fit_transform(np.array(data['Age']).reshape(-1, 1))
# plotting the data
sns.boxplot(data=scaled)This time we were able to transform the data and normalize it.
Summary
The min-max scalar form of normalization uses the mean and standard deviation to box all the data into a range lying between a certain min and max value. For most purposes, the range is set between 0 and 1. In this short article, we learned how the sklearn minmaxscaler works and we implemented it on various datasets to normalize the data by solving different examples.