
Do you want to know how the random state in sklearn module works and how it affects the formation of clusters? Well, here we go!
As we know, machine learning is all about data manipulation. Mostly, we divide the data into testing and training parts in order to evaluate the performance of the model. To make things fair, this splitting should be random, and in sklearn module, the random state is used. The random state is used to set the seed for the random generator so that we can ensure that the results that we get can be reproduced. Because the nature of splitting the data in train and test is randomized, we would get different data assigned to the train and test data unless you can control for the random factor. In this article, we will discuss how the random state works by taking a real dataset. Moreover, the random state in clustering also affects the formation of clusters as well and we will discuss it as well.
You may also like to do 3d Visualizations using various methods.
What is the Random State in Sklearn Module?
Scikit-learn is an open-source data analysis library and the gold standard for Machine Learning (ML) in the Python ecosystem. Key concepts and features include Algorithmic decision-making methods, including Classification: identifying and categorizing data based on patterns. As it contains a lot of Machine learning models already implemented, we can just import those models and train them on the dataset. In order to know how well the model will perform, we mostly divide the dataset into testing and training parts so that we can train the model first and then test the performance of the model using the testing data. Now, this splitting is fully randomized, which means every time we split the data, every time there will be different data in the testing part which is not what we want. The random state fixed and set specific random data to the testing and training parts..
How Does the Random State Work in Sklearn Module?
As of now, you have a basic concept of what the random state is and how it works. IWe will go further into depth and will try to understand the random state in sklearn module by implementing the random state in Python. For simplicity, we will create a random dataset and then split the data into testing and training parts using the random state in sklearn.
import pandas as pd
# assign data of lists.
data = {'Name': ['A', 'B', 'C', 'D','E','F','G'], 'Age': [20, 21, 19, 18, 2, 23, 56]}
# Create DataFrame
df = pd.DataFrame(data)
# Print the output.
print(df) Now, let us split the dataset into inputs and outputs. Then we will split the dataset into testing and training parts and we will fix the random state to 1.
# splitting data into input and output
X = df['Name']
y = df['Age']
# importing the module
from sklearn.model_selection import train_test_split
# random state in sklearn to 1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=1
# printing the testind and training parts
print("Trainig part is :\n", X_train)
print("Testing part is :\n", X_test)Output:
Trainig part is :
0 A
4 E
3 D
5 F
Name: Name, dtype: object
Testing part is :
6 G
2 C
1 B
Name: Name, dtype: objectThe data has been randomly assigned to testing and training parts, but if you run the same code again, the values will not change. Because the random state is fixed which means each time we run the code, each time we will get the same randomly distributed data. But if we change the value of the random state, then we will get different values as shown below:
# random state is fixed to 10
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=10)
# printing the testind and training parts
print("Trainig part is :\n", X_train)
print("Testing part is :\n", X_test)Output:
Trainig part is :
3 D
4 E
5 F
1 B
Name: Name, dtype: object
Testing part is :
2 C
6 G
0 A
Name: Name, dtype: object
This time we got different values for the testing and training parts because we changed the value of the random state.
Random State in k-means Clustering
One of the important things to note is that random state has a huge effect on the formation of clusters in clustering algorithms. Here, we will take the K-means clustering algorithm and will see how the formation of clusters is affected by changing the random state in sklearn.
Let us create a random dataset and visualize using a scatter plot.
import numpy as np
# get a random matrix of size (3, 3) in the range [0, 100]
matrix = np.random.random((1000, 2)) * 100
# importing the module
import matplotlib.pyplot as plt
# image size
plt.figure(figsize=(10,5))
# ploting scatered graph
plt.scatter(matrix[:,0], y=matrix[:,1], c='m')Output:
We have a fully randomly created dataset. Now, we will apply the k-means clustering with different random states to see how the formation of clusters changes.
# importing the k-means
from sklearn.cluster import KMeans
# ploting in line plots
fig, ax = plt.subplots(1, 3, gridspec_kw={'wspace': 0.3}, figsize=(15,5))
# k-means clustering in Python
for i in range(3):
km = KMeans(n_clusters = 3, init='random', n_init=1, random_state=i)
km.fit(matrix)
ax[i].scatter(x= matrix[:,0], y=matrix[:,1], c= km.labels_);Output:
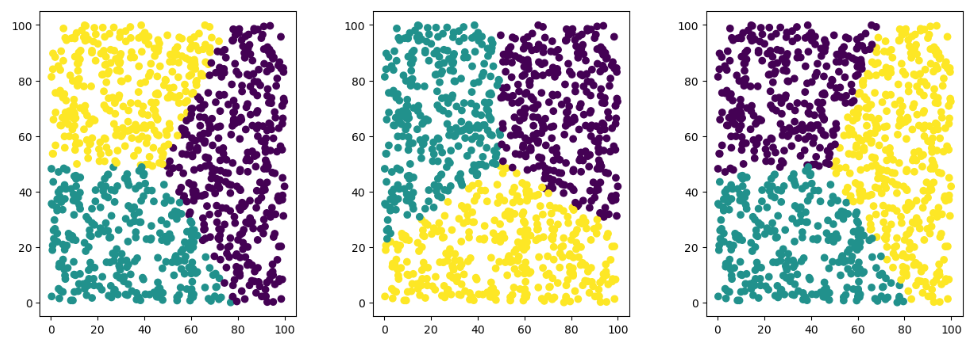
As you can see, each time we change the random state, we get different clusters. So, it is important to know what value of random state produces optimum clusters.
Summary
The random state is simply the lot number of the set generated randomly in any operation. We can specify this lot number whenever we want the same set again. The random state in sklearn has a great impact on the performance of the model as it specifies the randomness of the data. Also, in clustering models, the random state helps to create clusters as well. In this article, we discuss how the random state in sklearn module works. Furthermore, we learned how the random state in sklearn module affects the formation of clusters in clustering models.