In general, we cannot analyze and apply machine learning models on a dataset that has some non-numeric values. For example, if we have a dataset having a column where we have the names of various colors. Such a dataset cannot be directly applied to the machine learning model as models use various mathematical formulae to give us some outputs. In such cases, we are required to convert the non-numeric columns in our dataset to numeric columns and this process is known as Encoding.
What is the Encoding Method?
The conversion of non-numeric values or categorical values to numeric ones is known as the encoding method. There are various ways of encoding methods. In this lesson, we are going to cover the three most commonly used ones.
- Label Encoding
- Dummy Variable / One-hot Encoding
- Replace method
Let us first create a data frame that contains some non-numeric values.
# creating a random dataset
import pandas as pd
data = {"Grade": ["A", 'A', 'B', 'C', 'A' ,'D', 'D']}
df = pd.DataFrame(data)
In order to know if the dataset had non-numeric values, we will simply find the general information about the data frame. In pandas, we can use the info() method which will give us information about the datatypes of each column.
# check if the dataset had non-numeric values
df.info()
Output:
<class 'pandas.core.frame.DataFrame'> RangeIndex: 7 entries, 0 to 6 Data columns (total 1 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Grade 7 non-null object dtypes: object(1) memory usage: 184.0+ bytes
In this output, each column will be shown its data type. In our case, as shown, the Dtype of the column Grade is an object which simply means, it is a non-numeric column. As a data scientist, we will always avoid having object data types in our data frame as the majority of models cannot be trained on such datasets.
Label Encoding in Python
Label encoding is one of the most commonly used encoding methods in Python. It assigns a unique integer value, starting from zero to every category in the dataset. For example, the first category/non-numeric value will get the value of zero and the next one will get one, and so on.
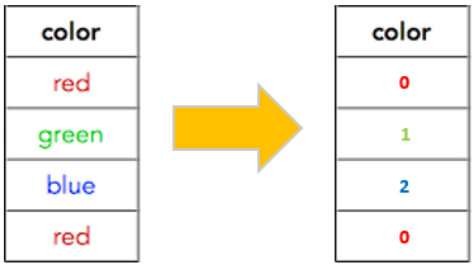
In this example, as you can see, the red category has been assigned a value of 0, the green has been assigned 1, and the blue 3. The numeric values will be assigned in alphabetical order.
One of the drawbacks of using the Label Encoding method on our dataset is that it gives a kind of ranking system. Let us imagine, we have 12 different colors and the first color will get the value of 0 and the last color will get the value of 11. Now, later when I apply a machine learning model, my model might be a little bit biased toward different colors because of having higher or lower numeric values.
In order to implement the Label Encoder, we have to import the Encoder from the Sklearn module.
# copying my original dataset
df1 = df.copy()
# importing the sklearn module
from sklearn.preprocessing import LabelEncoder
# initialize the model
label = LabelEncoder()
# fit the dataset
df1['Grade'] = label.fit_transform(df1['Grade'])
df
Once you get the output, you will notice that the Grades columns will be assigned by numeric values starting from 0 onwards.
In the example above, the fit_transform() method will take the column with the non-numeric values and then transform the values to numeric ones and store them back in the same column.
Dummy Variable in Pandas
Dummy variables or one-hot encoding method simply reduces the biases in the model. Unlike the Label Encoder, which assigns a unique integer value to every category, the one hot encoding method will assign a unique column to every category and put either 0 or 1 in the column.
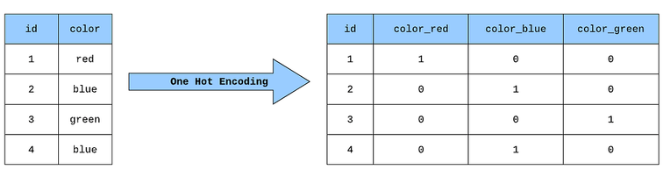
In the example, we again have a column representing three different colors. When one hot encoder is applied to this dataset, it generates a unique column for every color. In our original data, the first color at index 1 was red, and in the encoded data, only the red column will be 1, and the rest of the columns will be zero. In pretty same way, in our original data, at index 2 the color was blue. This means in the encoded data, only the blue column will be 1, and the rest will be zeros.
One of the limitations of this method is that it increases the dimensions of the dataset. This might now increase the training time of a machine learning model.
In order to implement one hot encoding method, you can either use the Sklearn module or Pandas. In this case, we will be using the Pandas module.
# copy the dataset
df2 = df.copy()
# apply the dummy variables
df2 = pd.get_dummies(df2, columns=['Grade'])
df2
Once you print the data frame after applying the one-hot encoding method, you will see new different columns assigned to each category in the dataset.
In some cases, if you have more than one column which has non-numeric values, then simply you will list them while applying the function.
# apply the dummy variables on multiple columns
df2 = pd.get_dummies(df2, columns=['Grade', 'Grade2', 'Grade3'])
It is highly recommended to apply the one-hot encoding method on only the input dataset. We will discuss this point in detail, once we start the machine learning section.
Replace method for Encoding
Let’s just assume that instead of assigning unique values starting from 0 or assigning unique columns, we want the values to be represented by values defined by us. In this case, let us say that we want Grade A to be represented by 90, Grade B by 80, and so on.
# copy dataset
df3 = df.copy()
# create a nested dictionary
encoded = {'Grade' : {"A": 90, "B": 80, 'C': 70, "D": 60}}
# apply replace method
df3.replace(encoded)
df3
In this case, we first have to define a nested dictionary. A nested dictionary is a dictionary that has another dictionary inside it. The outer key should represent the column name and the inder dictionary should pair the non-numeric value with a numeric value.
Summary
In this lesson, we discussed the encoding methods in Python which can be applied on a dataset to convert the non-numeric categorical values to numeric one.